
Overview
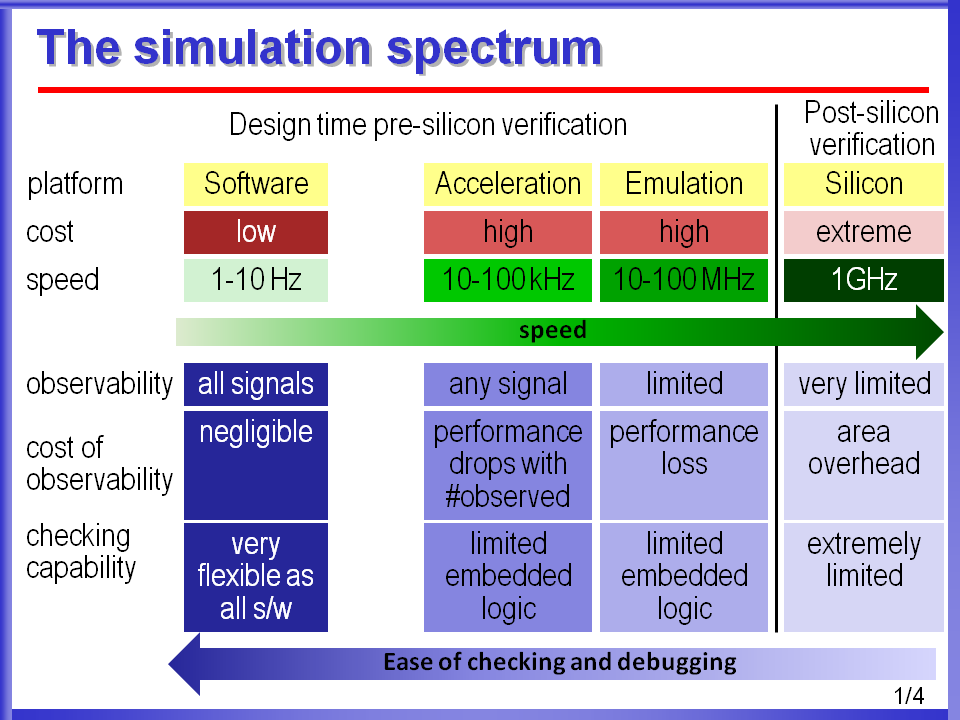
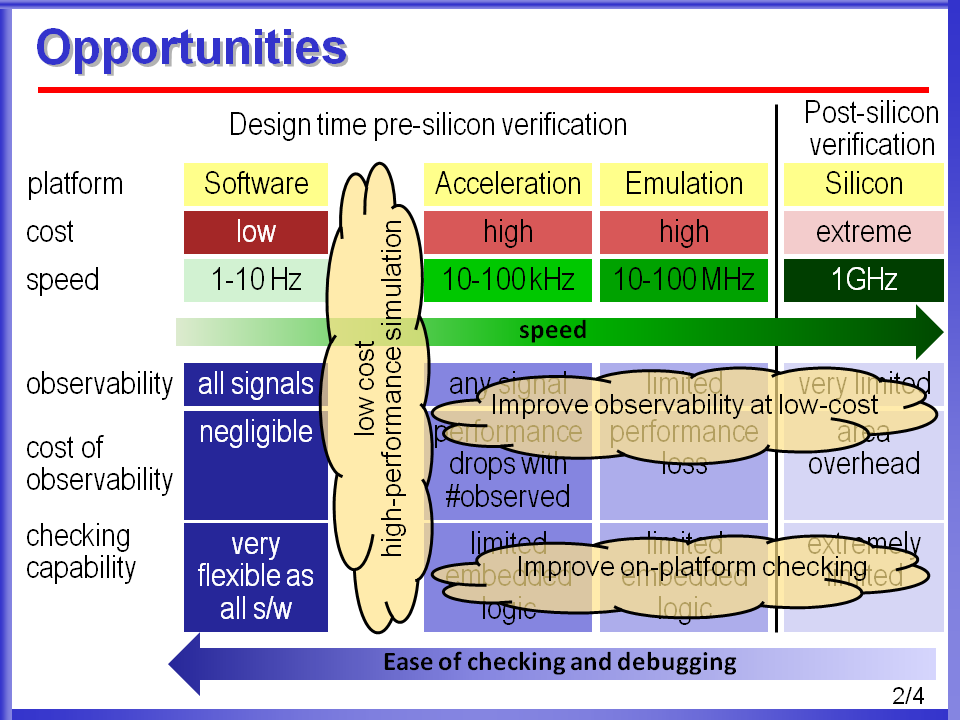
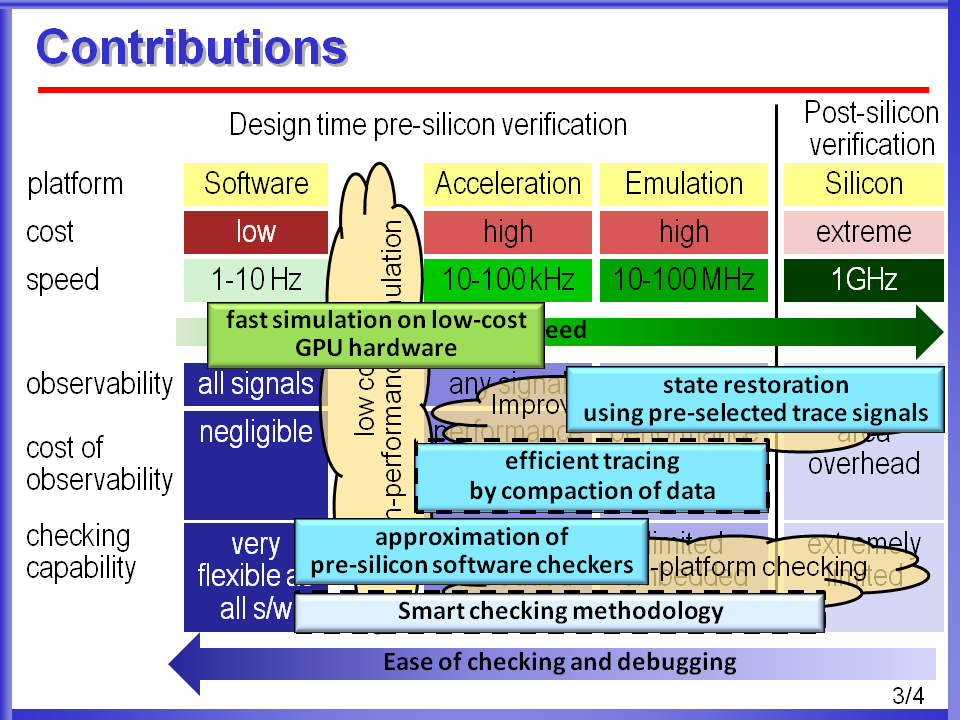
My research has explored ways to achieve high-performance simulation of digital designs (at different abstraction levels: behavioral, gate-level etc) using low-cost massively parallel processors, such as GPUs as an accelerator. However high-performance simulation alone is not enough to solve the verification challenge imposed by today's complex digital designs. Most of the checking/debugging features that are helpful during software simulation of a hardware design does not move forward to high-performance simulation platforms, such as accelerators, emulators or post-silicon in the extreme case. Hence, I have also investigated how to bring in the ease of checking/debugging in software simulation into the high-performance simulation platforms incurring minimal overhead.
Research Projects
Improving validation/debug support in acceleration/emulation/post-silicon platforms
Checking Architectural Outputs Instruction-By-Instruction on Acceleration Platforms
summary of project
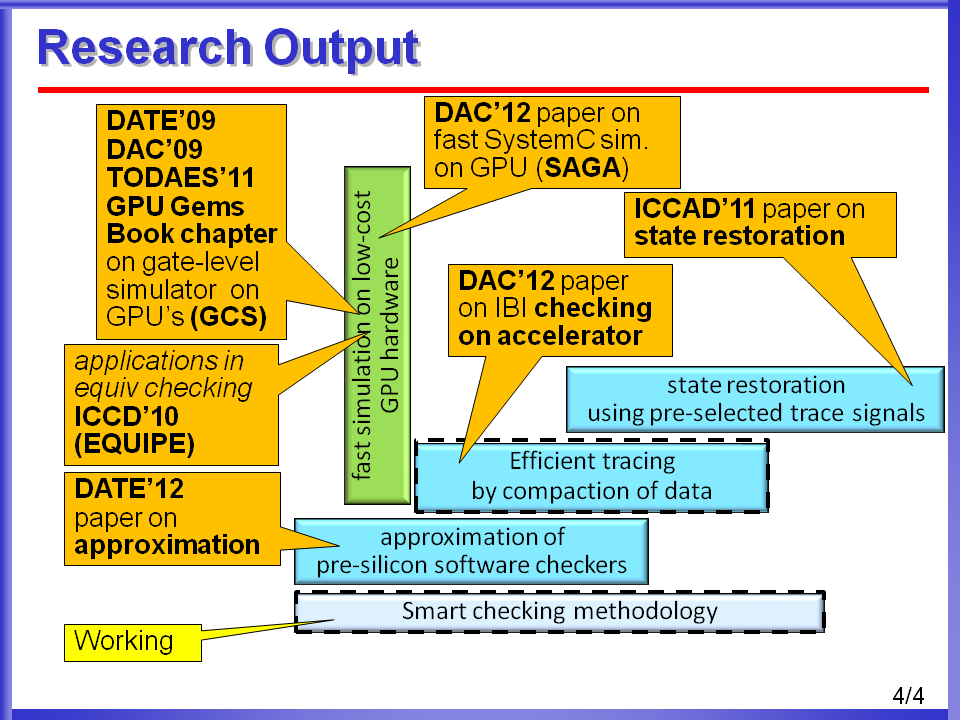
Simulation-based verification is an integral part of a modern micro-processor’s design effort. Commonly, several checking techniques are deployed alongside the simulator to detect and localize each functional bug manifestation. Among these, a widespread technique entails comparing a microprocessor design’s outputs with a golden model at the architectural granularity, instruction-by-instruction. However, due to exponential growth in design complexity, the performance of software-based simulation falls far short of achieving an acceptable level of coverage, which typically requires billions of simulation cycles. Hence, verification engineers rely on simulation acceleration platforms. Unfortunately, the intrinsic characteristics of these platforms make the adoption of the checking solutions mentioned above a challenging goal: for instance, the lockstep execution of a software checker together with the design’s simulation is no longer feasible. To address this challenge we propose an innovative solution for instruction-by-instruction (IBI) checking tailored to acceleration platforms. We provide novel design techniques to decouple event tracing from checking by including specialized tracing logic and by adding a post-simulation checking phase. Note that simulation performance in acceleration platforms degrades when increasing the number of signals that are traced; hence, it is imperative to generate a compact summary of the information required for checking, collecting and tracing only a few bits of information per cycle. This work was published in a paper at DAC'12.
Approximating Checkers for Simulation Acceleration
summary of project
Simulation-based functional verification is the key validation methodology the industry. The performance of logic simulators, however, is not sufficient to attain acceptable verifi-cation coverage on large industrial designs within the time-frame available. Acceleration platforms are a valuable addition to the verification effort in that they can provide much higher coverage in less time. Unfortunately, these platforms do not provide the rich checking capability of software-based simulation. We propose a novel solution to deploy those complex check- ers, typical of simulation-based environments, onto acceleration platforms. To this end, checkers must be transformed into synthesizable, compact logic blocks with bug-detection capabilities similar to that of their software counterparts. Our “approximate checkers” trade off logic complexity with bug detection accuracy by leveraging novel techniques to approximate complex software checkers into small synthesizable hardware blocks, which can be simulated along with the design on an acceleration platform. We present a general checker taxonomy, propose a range of approximation techniques based on a checker’s characteristic and provide metrics for evaluating its bug detection capabilities. This work was published as a DATE'12 paper.
Simulation-based Signal Selection for State Restoration in Silicon Debug
summary of project
Post-silicon validation has become a crucial part of modern integrated circuit design to capture and eliminate functional bugs that escape pre-silicon verification. The most critical roadblock in post-silicon validation is the limited observability of internal signals of a design, since this aspect hinders the ability to diagnose detected bugs. A solution to address this issue leverage trace buffers: these are register buffers embedded into the design with the goal of recording the value of a small number of state elements, over a time interval, triggered by a user-specified event. Due to the trace buffer’s area overhead, only a very small fraction of signals can be traced. Thus, the selection of which signals to trace is of paramount importance in post-silicon debugging and diagnosis. Ideally, we would like to select signals enabling the maximum amount of reconstruction of internal signal values. Several signal selection algorithms for post-silicon debug have been proposed in the literature: they rely on a probability-based state-restoration capacity metric coupled with a greedy algorithm. In this work we propose a more accurate restoration capacity metric, based on simulation information, and present a novel algorithm that overcomes some key shortcomings of previous solutions. We show that our technique provides up to 34% better state restoration compared to all previous techniques while showing a much better trend with increasing trace buffer size. This work was published in a paper at ICCAD'11.
Towards high-performance simulation on low-cost parallel hardware (GPUs)
SAGA: SystemC Acceleration on GPU Architectures
summary of project
SystemC is a widespread language for HW/SW system simulation and design exploration, and thus a key development platform in embedded system design. However, the growing complexity of SoC designs is having an impact on simulation performance, leading to limited SoC exploration potential, which in turns affects development and verification schedules and time-to-market for new designs. Previous efforts have attempted to parallelize SystemC simulation, targeting both multiprocessors and GPUs. However, for practical designs, those approaches fall far short of satisfactory performance. This paper proposes SAGA, a novel simulation approach that fully exploits the intrinsic parallelism of RTL SystemC descriptions, targeting GPU platforms. By limiting synchronization events with ad-hoc static scheduling and separate independent dataflows, we shows that we can simulate complex SystemC descriptions up to 16 times faster than traditional simulators. This work was published as a DAC'12 paper.
EQUIPE: Parallel equivalence checking with GP-GPUs
summary of project
Combinational equivalence checking (CEC) is a main-stream application in Electronic Design Automation used to determine the equivalence between two combinational netlists. Tools performing CEC are widely deployed in the design flow to determine the correctness of synthesis transformations and optimizations. One of the main limitations of these tools is their scalability, as industrial scale designs demand time-consuming computation. In this work we propose EQUIPE, a novel combinational equivalence checking solution, which leverages the massive parallelism of modern general purpose graphic processing units. EQUIPE reduces the need for hard-to-parallelize engines, such as BDDs and SAT, by taking advantage of algorithms well-suited to concurrent implementation. This work was published in a paper at ICCD'10.
GCS: GPU ACCELERATED GATE-LEVEL SIMULATION
summary of project
In recent years, the verification of digital designs has become one of the most challenging, time consuming and critical tasks in the entire hardware development process. Within this area, the vast majority of the verification effort in industry relies on logic simulation tools. However, logic simulators deliver limited performance when faced with vastly complex modern systems, especially synthesized netlists. The consequences are poor design coverage, delayed product releases and bugs that escape into silicon.Noticing the high degree of parallelism available in the problem, the problem presented a good match for the parallelism present in modern General Purpose Graphics Processors (GP-GPUs). We leveraged the massively parallel processing capabilities incorporated in modern GPU's with the aid of GP-GPU software interface (NVIDIA CUDA specifically for this project) to develop a novel gate-level circuit simulator, called GCS.
Several novel algorithms in regards to partitioning the circuit to suit the GP-GPU computing model were developed. They expose the paralellism available in the problem to the parallelism present in the execution hardware. This simulator delivers an order-of-magnitude performance improvement over state of the art commercial simulators. The first version of this simulator functioned in an oblivious fashion and is described in this paper published in DATE'09. This simulator was further developed to function in a more efficient event-driven fashion using novel segmentation techniques, this work is described in this paper published in DAC'09.